
Maybe I'm speaking out of turn from the sidelines, but just curious to ask a leading question...
What is the purpose of the Continuous Integration system?
I notice Travis has not had a green build for nearly 120 days https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds since Build #603... https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/200671152
I'd guess that makes it harder to identify which "new" commits introduce "new" defects. It was tough for me trying to categorise the historical failures to understand what might be required to make them green.
For example, lately the usual failure has been just a single job... macos32x64 squeak.sista.spur. which last worked 22 days ago in Build #713 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/228902233 but there are other failures in builds that obscure that fact, way back to #603. Only an exhaustive search through all builds reveals this.
For example, recent Build #748 has macos32x64 squeak.sista.spur as its only failure https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/236010112 but then #750,#751, #752, #753 introduce other failures.
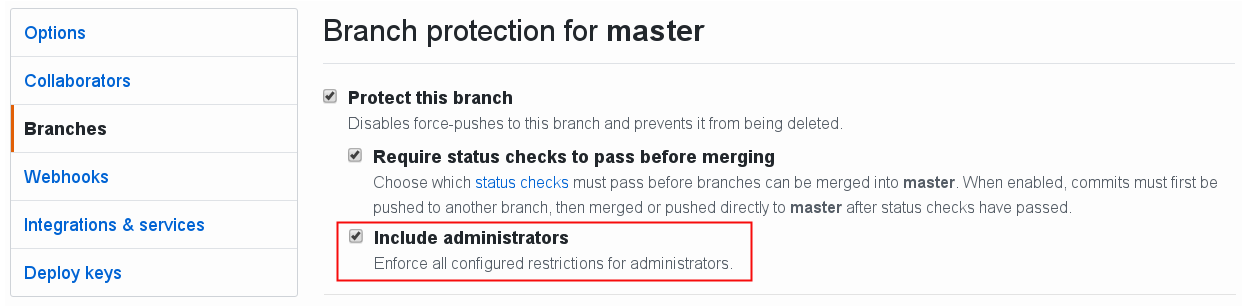
Perhaps a contributing factor is commits being pushed directly to the server Cog branch, with CI tests only running after they are integrated. I guess that was done to keep the workflow similar for those moving from subversion to git. However it seems to lose some value of CI in "preventing" build failures from entering the repository. After a year of using git maybe this workflow could be reconsidered? Perhaps turn turn on branch protection for administrators and "force" all commits to the server Cog branch to first pass CI testing?
Of course needing to submit everything via PRs adds workflow overhead, but some workflows might minimise the impact. So I can't argue whether the benefit is worth it, since I'm not working in the VM every day. I'm just bumping the status quo to table the question for discussion.
cheers -ben
P.S. Should macos32x64 squeak.sista.spur be fixed, or temporarily removed from the build matrix? A continually failing build seems to serve no purpose, whereas green builds should be a great help to noticing new failures.
{kind=link}

+1
Exactly what I named continuous desintegration in recent post http://forum.world.st/OpenSmalltalk-opensmalltalk-vm-24bea9-Fix-compilation-...
2017-05-28 15:46 GMT+02:00 Ben Coman btc@openinworld.com:
Maybe I'm speaking out of turn from the sidelines, but just curious to ask a leading question...
What is the purpose of the Continuous Integration system?
I notice Travis has not had a green build for nearly 120 days https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds since Build #603... https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/200671152
I'd guess that makes it harder to identify which "new" commits introduce "new" defects. It was tough for me trying to categorise the historical failures to understand what might be required to make them green.
For example, lately the usual failure has been just a single job... macos32x64 squeak.sista.spur. which last worked 22 days ago in Build #713 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/228902233 but there are other failures in builds that obscure that fact, way back to #603. Only an exhaustive search through all builds reveals this.
For example, recent Build #748 has macos32x64 squeak.sista.spur as its only failure https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/236010112 but then #750,#751, #752, #753 introduce other failures.
Perhaps a contributing factor is commits being pushed directly to the server Cog branch, with CI tests only running after they are integrated. I guess that was done to keep the workflow similar for those moving from subversion to git. However it seems to lose some value of CI in "preventing" build failures from entering the repository. After a year of using git maybe this workflow could be reconsidered? Perhaps turn turn on branch protection for administrators and "force" all commits to the server Cog branch to first pass CI testing?
Of course needing to submit everything via PRs adds workflow overhead, but some workflows might minimise the impact. So I can't argue whether the benefit is worth it, since I'm not working in the VM every day. I'm just bumping the status quo to table the question for discussion.
cheers -ben
P.S. Should macos32x64 squeak.sista.spur be fixed, or temporarily removed from the build matrix? A continually failing build seems to serve no purpose, whereas green builds should be a great help to noticing new failures.

+1 for using more (feature) branches for OSVM development
Also, there's no need to temporarily remove a build. We can flag builds as "allow to fail" [1].
[1] https://docs.travis-ci.com/user/customizing-the-build#Rows-that-are-Allowed-...

Hi Ben,
On Sun, May 28, 2017 at 6:46 AM, Ben Coman btc@openinworld.com wrote:
Maybe I'm speaking out of turn from the sidelines, but just curious to ask a leading question...
What is the purpose of the Continuous Integration system?
One thing for me is to identify when I've made a mistake Yes it is selfish of me to want to break a build, but in some way those of us who are active VM developers must be able to commit and see what fails, especially when we have a large platform and VM variant spread.
IMO what needs to be added is a way of marking commits as good. I think we should continue to be allowed to break the build (something we do unintentionally). But we need a set of criteria to mark a build as fit for release and have a download URL from which we obtain the latest releasable VM.
I agree with Fabio that if we want the CI server to be as green as possible marking builds which have been failing for a long time as "allowed to fail" is a good idea. But it also has to be brought to people's attention that there are such builds.
As far as the Sista and Locoed VMs go these are experimental, as would a threaded FFI VM, something we may have later this year. It would be nice to segregate the standard VMs that are already in production from these experimental builds so that failures within the experimental set don't affect the status of the production VMs. I'd rather se that segregation than mark certain builds as allowed to fail.
I notice Travis has not had a green build for nearly 120 days https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds since Build #603... https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/200671152
I'd guess that makes it harder to identify which "new" commits introduce "new" defects. It was tough for me trying to categorise the historical failures to understand what might be required to make them green.
For example, lately the usual failure has been just a single job... macos32x64 squeak.sista.spur. which last worked 22 days ago in Build #713 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/228902233 but there are other failures in builds that obscure that fact, way back to #603. Only an exhaustive search through all builds reveals this.
For example, recent Build #748 has macos32x64 squeak.sista.spur as its only failure https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/236010112 but then #750,#751, #752, #753 introduce other failures.
Perhaps a contributing factor is commits being pushed directly to the server Cog branch, with CI tests only running after they are integrated. I guess that was done to keep the workflow similar for those moving from subversion to git. However it seems to lose some value of CI in "preventing" build failures from entering the repository. After a year of using git maybe this workflow could be reconsidered? Perhaps turn turn on branch protection for administrators and "force" all commits to the server Cog branch to first pass CI testing?
That's not the reason. then reason is so that we can see if a commit is good across the entire matrix. If there's no way to discover what elements of the matrix are affected by a build then that will reduce my productivity.
Another thing that would reduce productivity would be having to commit to a clone of the CI and then only being able to push to the Cog branch when the clone succeeds, as this would introduce hours of delay. Much better is a system of tests that then selects good builds, and something that identifies a good build as one in which the full set of production VMs have passed their tests. And of course one wants to be able to see the converse.
Of course needing to submit everything via PRs adds workflow overhead, but some workflows might minimise the impact. So I can't argue whether the benefit is worth it, since I'm not working in the VM every day. I'm just bumping the status quo to table the question for discussion.
I don't see the benefit of submitting everything via PR when the need is to define the latest releasable VM, which needs additional testing and packaging, not just green builds.
cheers -ben
P.S. Should macos32x64 squeak.sista.spur be fixed, or temporarily removed from the build matrix? A continually failing build seems to serve no purpose, whereas green builds should be a great help to noticing new failures.
I hope it can be both fixed and put in an experimental matrix.
_,,,^..^,,,_ best, Eliot
On Tue, May 30, 2017 at 3:25 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Ben,
On Sun, May 28, 2017 at 6:46 AM, Ben Coman btc@openinworld.com wrote:
Maybe I'm speaking out of turn from the sidelines, but just curious to ask a leading question...
What is the purpose of the Continuous Integration system?
One thing for me is to identify when I've made a mistake Yes it is selfish of me
Thats fine :). We need you to keep to productive ;) I'm trying to understand your perspective and needs to see if the workflow can be tuned without slowing you down too much.
to want to break a build, but in some way those of us who are active VM developers must be able to commit and see what fails, especially when we have a large platform and VM variant spread.
Creating a PR automatically runs the CI tests. So you'll get that.
I'd propose your continuous work would occur in a single Cog-eem branch. Pulling from the server-Cog branch would be the same as your current workflow. Pushing to the server as a PR would automatically the CI tests and automatically integrate into the server-Cog branch upon success. There is nothing stopping your work continuing in your Cog-eem branch while the CI tests are running, just the same as you currently continue working in your local-Cog branch.
We can probably devise an efficient way for you to issue the pull request from the command line - something like... https://github.com/github/hub/issues/1219 https://stackoverflow.com/questions/4037928/can-you-issue-pull-requests-from...
IMO what needs to be added is a way of marking commits as good. I think we should continue to be allowed to break the build (something we do unintentionally).
In my proposal, you break builds in your own Cog-eem branch, and when the CI build succeeds its automatically integrated into the mainline server-Cog branch. If explicit no-ff merge points are maintained, then that may be sufficient to mark a good-build.
But we need a set of criteria to mark a build as fit for release and have a download URL from which we obtain the latest releasable VM.
Marking a good-build as a release-build would be a further and separate step. btw, I thought "master" branch was going to track "release-builds" ?
I agree with Fabio that if we want the CI server to be as green as possible marking builds which have been failing for a long time as "allowed to fail" is a good idea. But it also has to be brought to people's attention that there are such builds.
I'm not sure the best way to do this. Perhaps upon "travis_sucess" would it be possible to scan the log to report allowed-failures of experimental builds?
As far as the Sista and Lowcode VMs go these are experimental, as would a threaded FFI VM, something we may have later this year.
Maybe these should be separate feature-branches with their own Travis build, which first only tests the feature specific build for quick turn around, and then triggers the production builds for further information.
It would be nice to segregate the standard VMs that are already in production from these experimental builds so that failures within the experimental set don't affect the status of the production VMs. I'd rather see that segregation than mark certain builds as allowed to fail.
The segregation might be done as a dependent build, so it is only started if the production build succeeds. But I would guess the later is quicker to implement, so can we do that first? Lets get the builds green asap, then move from there.
@Fabio, what is the actual Travis change that would effect this?
I notice Travis has not had a green build for nearly 120 days
https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds since Build #603... https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/200671152
I'd guess that makes it harder to identify which "new" commits introduce "new" defects. It was tough for me trying to categorise the historical failures to understand what might be required to make them green.
For example, lately the usual failure has been just a single job... macos32x64 squeak.sista.spur. which last worked 22 days ago in Build #713 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/228902233 but there are other failures in builds that obscure that fact, way back to #603. Only an exhaustive search through all builds reveals this.
For example, recent Build #748 has macos32x64 squeak.sista.spur as its only failure https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/236010112 but then #750,#751, #752, #753 introduce other failures.
Perhaps a contributing factor is commits being pushed directly to the server Cog branch, with CI tests only running after they are integrated. I guess that was done to keep the workflow similar for those moving from subversion to git. However it seems to lose some value of CI in "preventing" build failures from entering the repository. After a year of using git maybe this workflow could be reconsidered? Perhaps turn turn on branch protection for administrators and "force" all commits to the server Cog branch to first pass CI testing?
That's not the reason. then reason is so that we can see if a commit is good across the entire matrix. If there's no way to discover what elements of the matrix are affected by a build then that will reduce my productivity.
You'll get that with a PR. But you'll get test-results before your code is integrated into the server-Cog branch.
Another thing that would reduce productivity would be having to commit to a clone of the CI and then only being able to push to the Cog branch when the clone succeeds, as this would introduce hours of delay.
Could you expand on this? I'm not sure what you mean by "clone of the CI". If you are continuously working in a Cog-eem branch there is no reason to stop work while the CI tests run. Any further commits pushed in your Cog-eem branch automatically update an open PR and the CI testing automatically runs again and automatically integrates into the server-Cog branch upon success.
Much better is a system of tests that then selects good builds, and something that identifies a good build as one in which the full set of production VMs have passed their tests. And of course one wants to be able to see the converse.
Of course needing to submit everything via PRs adds workflow overhead, but some workflows might minimise the impact. So I can't argue whether the benefit is worth it, since I'm not working in the VM every day. I'm just bumping the status quo to table the question for discussion.
I don't see the benefit of submitting everything via PR when the need is to define the latest releasable VM, which needs additional testing and packaging, not just green builds.
Having green incremental commit-builds is a separate issue from having a releasable build. The former provides tighter tracking of breakages. For example, when someone else's commits break the build, this confounds the test results of your own commits and I guess introduces at least some minor delay to work out.
Just because there is a higher-level need, doesn't mean the lesser commit-builds are unimportant. They are a pre-requisite for release-builds. Can we do the easier step first.
cheers -ben
P.S. Should macos32x64 squeak.sista.spur be fixed, or temporarily removed from the build matrix? A continually failing build seems to serve no purpose, whereas green builds should be a great help to noticing new failures.
I hope it can be both fixed and put in an experimental matrix.
_,,,^..^,,,_ best, Eliot
cheers -ben
P.S just bumped into an interesting (short) article "a few conceptual difficulties really stand out." https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/
P.P.S. I think in a really ideal system, once Travis vetted the final commit of the PR and was ready to merge, it would go back and test each interposing commit and squash it if its build failed, so that every commit in the repo was a green build. But I guess that is just dreaming.

Hi,
I think one problem we have now is that we cannot know if the build will work or not, then sometimes we generate binaries (which are published on bintray and in the case of pharo on files.pharo.org http://files.pharo.org/) and we don’t know if they will work at all. this is because development branch and stable branch are the same (which basically means we do not have a stable branch, heh).
let me explain how I would like to handle this instead:
1) We need a stable branch, let’s say is Cog 2) We also need a development branch, let’s call it CogDev
All commits and contributions should be in CogDev. Then when Eliot decides a build is good enough for people to use, he should merge changes to stable (Cog). Before you think is too much work, is as easy as doing:
$ git checkout Cog $ git merge CogDev $ git push $ git checkout CogDev
(which can be easily put in a script called “promote-stable” or whatever).
this way we have the benefits of both worlds.
In any case, in the “pharo side” of things, we keep a parallel CI process who does this:
1) there is a development branch that keep all sources we need: the osvm *and* all monticello packages (filetree format) acting as a mirror that merges changes and executes all building process (including generating sources) and testing (we run all pharo tests as a way to test the VM). This is done just for being sure the CI is green and no artifact is created. This is how I have early reported problem in VM generation before. 2) in parallel the build follows the “normal” process on opensmalltalk-vm and everything is build there. This generates a “latest” build which is published in pharo servers so people can test (but this binary could be wrong as is not something declared as “stable” 3) time to time, when Eliot says “this VM is good”, I manually promote the latest vm to stable vm. This is the step that I could avoid if we have two separated branchs :)
well, that’s my 2c
Esteban
On 30 May 2017, at 05:43, Ben Coman btc@openInWorld.com wrote:
On Tue, May 30, 2017 at 3:25 AM, Eliot Miranda <eliot.miranda@gmail.com mailto:eliot.miranda@gmail.com> wrote:
Hi Ben,
On Sun, May 28, 2017 at 6:46 AM, Ben Coman <btc@openinworld.com mailto:btc@openinworld.com> wrote:
Maybe I'm speaking out of turn from the sidelines, but just curious to ask a leading question...
What is the purpose of the Continuous Integration system?
One thing for me is to identify when I've made a mistake Yes it is selfish of me
Thats fine :). We need you to keep to productive ;) I'm trying to understand your perspective and needs to see if the workflow can be tuned without slowing you down too much.
to want to break a build, but in some way those of us who are active VM developers must be able to commit and see what fails, especially when we have a large platform and VM variant spread.
Creating a PR automatically runs the CI tests. So you'll get that.
I'd propose your continuous work would occur in a single Cog-eem branch. Pulling from the server-Cog branch would be the same as your current workflow. Pushing to the server as a PR would automatically the CI tests and automatically integrate into the server-Cog branch upon success. There is nothing stopping your work continuing in your Cog-eem branch while the CI tests are running, just the same as you currently continue working in your local-Cog branch.
We can probably devise an efficient way for you to issue the pull request from the command line - something like... https://github.com/github/hub/issues/1219 https://github.com/github/hub/issues/1219 https://stackoverflow.com/questions/4037928/can-you-issue-pull-requests-from... https://stackoverflow.com/questions/4037928/can-you-issue-pull-requests-from-the-command-line-on-github
IMO what needs to be added is a way of marking commits as good. I think we should continue to be allowed to break the build (something we do unintentionally).
In my proposal, you break builds in your own Cog-eem branch, and when the CI build succeeds its automatically integrated into the mainline server-Cog branch. If explicit no-ff merge points are maintained, then that may be sufficient to mark a good-build.
But we need a set of criteria to mark a build as fit for release and have a download URL from which we obtain the latest releasable VM.
Marking a good-build as a release-build would be a further and separate step. btw, I thought "master" branch was going to track "release-builds" ?
I agree with Fabio that if we want the CI server to be as green as possible marking builds which have been failing for a long time as "allowed to fail" is a good idea. But it also has to be brought to people's attention that there are such builds.
I'm not sure the best way to do this. Perhaps upon "travis_sucess" would it be possible to scan the log to report allowed-failures of experimental builds?
As far as the Sista and Lowcode VMs go these are experimental, as would a threaded FFI VM, something we may have later this year.
Maybe these should be separate feature-branches with their own Travis build, which first only tests the feature specific build for quick turn around, and then triggers the production builds for further information.
It would be nice to segregate the standard VMs that are already in production from these experimental builds so that failures within the experimental set don't affect the status of the production VMs. I'd rather see that segregation than mark certain builds as allowed to fail.
The segregation might be done as a dependent build, so it is only started if the production build succeeds. But I would guess the later is quicker to implement, so can we do that first? Lets get the builds green asap, then move from there.
@Fabio, what is the actual Travis change that would effect this?
I notice Travis has not had a green build for nearly 120 days https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds since Build #603... https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/200671152 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/200671152
I'd guess that makes it harder to identify which "new" commits introduce "new" defects. It was tough for me trying to categorise the historical failures to understand what might be required to make them green.
For example, lately the usual failure has been just a single job... macos32x64 squeak.sista.spur. which last worked 22 days ago in Build #713 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/228902233 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/228902233 but there are other failures in builds that obscure that fact, way back to #603. Only an exhaustive search through all builds reveals this.
For example, recent Build #748 has macos32x64 squeak.sista.spur as its only failure https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/236010112 https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/builds/236010112 but then #750,#751, #752, #753 introduce other failures.
Perhaps a contributing factor is commits being pushed directly to the server Cog branch, with CI tests only running after they are integrated. I guess that was done to keep the workflow similar for those moving from subversion to git. However it seems to lose some value of CI in "preventing" build failures from entering the repository. After a year of using git maybe this workflow could be reconsidered? Perhaps turn turn on branch protection for administrators and "force" all commits to the server Cog branch to first pass CI testing?
That's not the reason. then reason is so that we can see if a commit is good across the entire matrix. If there's no way to discover what elements of the matrix are affected by a build then that will reduce my productivity.
You'll get that with a PR. But you'll get test-results before your code is integrated into the server-Cog branch.
Another thing that would reduce productivity would be having to commit to a clone of the CI and then only being able to push to the Cog branch when the clone succeeds, as this would introduce hours of delay.
Could you expand on this? I'm not sure what you mean by "clone of the CI". If you are continuously working in a Cog-eem branch there is no reason to stop work while the CI tests run. Any further commits pushed in your Cog-eem branch automatically update an open PR and the CI testing automatically runs again and automatically integrates into the server-Cog branch upon success.
Much better is a system of tests that then selects good builds, and something that identifies a good build as one in which the full set of production VMs have passed their tests. And of course one wants to be able to see the converse.
Of course needing to submit everything via PRs adds workflow overhead, but some workflows might minimise the impact. So I can't argue whether the benefit is worth it, since I'm not working in the VM every day. I'm just bumping the status quo to table the question for discussion.
I don't see the benefit of submitting everything via PR when the need is to define the latest releasable VM, which needs additional testing and packaging, not just green builds.
Having green incremental commit-builds is a separate issue from having a releasable build. The former provides tighter tracking of breakages. For example, when someone else's commits break the build, this confounds the test results of your own commits and I guess introduces at least some minor delay to work out.
Just because there is a higher-level need, doesn't mean the lesser commit-builds are unimportant. They are a pre-requisite for release-builds. Can we do the easier step first.
cheers -ben
P.S. Should macos32x64 squeak.sista.spur be fixed, or temporarily removed from the build matrix? A continually failing build seems to serve no purpose, whereas green builds should be a great help to noticing new failures.
I hope it can be both fixed and put in an experimental matrix.
_,,,^..^,,,_ best, Eliot
cheers -ben
P.S just bumped into an interesting (short) article "a few conceptual difficulties really stand out." https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/ https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/
P.P.S. I think in a really ideal system, once Travis vetted the final commit of the PR and was ready to merge, it would go back and test each interposing commit and squash it if its build failed, so that every commit in the repo was a green build. But I guess that is just dreaming.

On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote:
- We need a stable branch, let’s say is Cog
- We also need a development branch, let’s call it CogDev
IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
Changes will move from primary developer (dev) for individual components on their own reference OS (or OSes) to full build (integration of all components on all supported OS plus regression tests) and then onto stable. The integration branch has to ensure that there are no major regressions before merging a change to stable.
Regards .. Subbu
On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote:
- We need a stable branch, let’s say is Cog
- We also need a development branch, let’s call it CogDev
IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
Changes will move from primary developer (dev) for individual components on their own reference OS (or OSes) to full build (integration of all components on all supported OS plus regression tests) and then onto stable. The integration branch has to ensure that there are no major regressions before merging a change to stable.
as I said… this will not happen, because nobody is “integrator” (and everybody is) :)
Esteban
Regards .. Subbu

On 31.05.2017, at 09:05, Esteban Lorenzano estebanlm@gmail.com wrote:
On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote:
- We need a stable branch, let’s say is Cog
- We also need a development branch, let’s call it CogDev
IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
Changes will move from primary developer (dev) for individual components on their own reference OS (or OSes) to full build (integration of all components on all supported OS plus regression tests) and then onto stable. The integration branch has to ensure that there are no major regressions before merging a change to stable.
as I said… this will not happen, because nobody is “integrator” (and everybody is) :)
exactly.
Esteban
Regards .. Subbu
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote:
On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote:
- We need a stable branch, let’s say is Cog 2) We also need a
development branch, let’s call it CogDev
IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
I proposed only three *branches*, not people. Splitting development into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I will defer to your experience. I do understand the difference between logical and practical in these matters.
Regards .. Subbu
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote:
On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote:
- We need a stable branch, let’s say is Cog 2) We also need a
development branch, let’s call it CogDev
IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
I proposed only three *branches*, not people. Splitting development into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs. The system must allow pushing an experiment through the build and test pipeline to learn of a piece of development's impact. An experiment may have to last for several months (for several reasons; the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of - select a generated source tree (e.g. spursrc vs spur64src) - use #ifdef's to select code in the C source - use plugins.int & plugins.ext to select a set of plugins A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build? For me a tested, versioned and named artifact is more useful than an all green build. An all read build is a red flag. A mostly green build is simply a failure to segregate production from in development artifacts.
Regards .. Subbu
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote:
On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote:
- We need a stable branch, let’s say is Cog 2) We also need a
development branch, let’s call it CogDev
IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
I proposed only three *branches*, not people. Splitting development into
two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference between
logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs. The system must allow pushing an experiment through the build and test pipeline to learn of a piece of development's impact. An experiment may have to last for several months (for several reasons; the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build? For me a tested, versioned and named artifact is more useful than an all green build. An all read build is a red flag. A mostly green build is simply a failure to segregate production from in development artifacts.
Hi Eliot, the main advantage of github is the social thing: - lower barrier of contributing via a better integration of tools (not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools), - and ease integration of many small contributions back. For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
Regards .. Subbu
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote:
On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote:
- We need a stable branch, let’s say is Cog 2) We also need a
development branch, let’s call it CogDev
IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
I proposed only three *branches*, not people. Splitting development
into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference between
logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs. The system must allow pushing an experiment through the build and test pipeline to learn of a piece of development's impact. An experiment may have to last for several months (for several reasons; the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build? For me a tested, versioned and named artifact is more useful than an all green build. An all read build is a red flag. A mostly green build is simply a failure to segregate production from in development artifacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
* to show that the CI builds are cared for
* allow newcomers to be confident that the tip they are working from is green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
* act timely to integrate, to encourage further contributions. If someone contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
Regards .. Subbu

Hi,
Just re the discussion of dev and stable branch, the original idea was that Cog is dev and master is stable. We never expected that people would use or recommend the Cog bintray builds for anything other than development.
I feel the only problem is that we need someone who merges to master when it is green. I think we have already protected the master branch in the way Ben suggested, i.e., you can only open a PR and merge it if the Travis build is all green.
The bintray deployment should not be taken as a source of stable builds. It is meant to be used by what Eliot calls brave souls who want to help to test the latest and possibly unstable changes.
Just my 2c
Tim
On Thu, 1 Jun 2017, 06:05 Ben Coman, btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote:
> On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote: > > On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote: > 1) We need a stable branch, let’s say is Cog 2) We also need a > development branch, let’s call it CogDev IMHO, three branches are required as a minimum - stable, integration and development because there are multiple primary developers in core Pharo working on different OS platforms.
but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
I proposed only three *branches*, not people. Splitting development
into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference
between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs. The system must allow pushing an experiment through the build and test pipeline to learn of a piece of development's impact. An experiment may have to last for several months (for several reasons; the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build? For me a tested, versioned and named artifact is more useful than an all green build. An all read build is a red flag. A mostly green build is simply a failure to segregate production from in development artifacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
to show that the CI builds are cared for
allow newcomers to be confident that the tip they are working from is
green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
- act timely to integrate, to encourage further contributions. If someone
contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
Regards .. Subbu
Hi Tim,
On May 31, 2017, at 11:53 PM, Tim Felgentreff timfelgentreff@gmail.com wrote:
Hi,
Just re the discussion of dev and stable branch, the original idea was that Cog is dev and master is stable. We never expected that people would use or recommend the Cog bintray builds for anything other than development.
I feel the only problem is that we need someone who merges to master when it is green. I think we have already protected the master branch in the way Ben suggested, i.e., you can only open a PR and merge it if the Travis build is all green.
I can do this. Ideally it would be either automatic or prompted. What I mean is that there should be a set of tests that are relevant n on images using the production subset of the VMs built from the Cog branch. Whenever the tests are all green then either I get sent an email prompting me to push to master, or a push to master occurs.
Maybe I can get into the habit of checking the status of the build a few hours after a commit. But a generated email would compensate for my, um, it's on the tip of my tongue, um, my, my memory! And an automated push would allow me to resume walking in front of busses.
The bintray deployment should not be taken as a source of stable builds. It is meant to be used by what Eliot calls brave souls who want to help to test the latest and possibly unstable changes.
Good. This makes perfect sense to me. Are there places in the configuration to add brief overview texts explaining this to the bintray download pages? It would be great to have a short paragraph that says these are development versions and directs to the master builds.
P.S. for master builds Gilad has noticed that there is no .msi for the newspeak builds (and I suspect there may be no .dmg). In e.g. build.win32x86/newspeak.cog.spur/installer is code to make the .msi for a newspeak vm. And the corresponding thing exists for making the Mac OS .dmg. Any brace souls feel up to trying to get them together be built?
Just my 2c
Tim
On Thu, 1 Jun 2017, 06:05 Ben Coman, btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier nicolas.cellier.aka.nice@gmail.com wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote:
>> On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote: >> >> On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote: >> 1) We need a stable branch, let’s say is Cog 2) We also need a >> development branch, let’s call it CogDev > IMHO, three branches are required as a minimum - stable, > integration and development because there are multiple primary > developers in core Pharo working on different OS platforms. but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
I proposed only three *branches*, not people. Splitting development into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs. The system must allow pushing an experiment through the build and test pipeline to learn of a piece of development's impact. An experiment may have to last for several months (for several reasons; the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do).
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build? For me a tested, versioned and named artifact is more useful than an all green build. An all read build is a red flag. A mostly green build is simply a failure to segregate production from in development artifacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
to show that the CI builds are cared for
allow newcomers to be confident that the tip they are working from is green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
act timely to integrate, to encourage further contributions. If someone contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
Regards .. Subbu
On Thu, Jun 1, 2017 at 10:38 PM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tim,
On May 31, 2017, at 11:53 PM, Tim Felgentreff timfelgentreff@gmail.com wrote:
Hi,
Just re the discussion of dev and stable branch, the original idea was that Cog is dev and master is stable. We never expected that people would use or recommend the Cog bintray builds for anything other than development.
But "master" ended up so far behind, recent changes would not get much
testing leading up to Pharo release... $ git log master 17 Aug 2016
You want to *encourage* people to use more recent VMs to get more feedback earlier.
I feel the only problem is that we need someone who merges to master when it is green. I think we have already protected the master branch in the way Ben suggested, i.e., you can only open a PR and merge it if the Travis build is all green.
I can do this. Ideally it would be either automatic or prompted. What I mean is that there should be a set of tests that are relevant n on images using the production subset of the VMs built from the Cog branch. Whenever the tests are all green then either I get sent an email prompting me to push to master, or a push to master occurs.
I think it would be useful to differentiate between different levels of stability depending on application and personal perspective. A. personal-stable -- stable "enough" for developer/student to use personally on their desktop -- might be optimistic if it passes all tests B. production-stable -- "bulletproof" for operating machinery and business systems - maybe when A has be in wide use for a while
btw, it occurs to be that "master" is a bit ambiguous. Perhaps for (B.) "master" could be renamed "production" https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/
and for (A.) maybe introduce "stable" or alternatively "validated" to mean all tests passed without the strong implication it is "stable".
Maybe I can get into the habit of checking the status of the build a few hours after a commit. But a generated email would compensate for my, um, it's on the tip of my tongue, um, my, my memory! And an automated push would allow me to resume walking in front of buses.
The bintray deployment should not be taken as a source of stable builds. It is meant to be used by what Eliot calls brave souls who want to help to test the latest and possibly unstable changes.
Good. This makes perfect sense to me. Are there places in the configuration to add brief overview texts explaining this to the bintray download pages? It would be great to have a short paragraph that says these are development versions and directs to the master builds.
P.S. for master builds Gilad has noticed that there is no .msi for the newspeak builds (and I suspect there may be no .dmg). In e.g. build.win32x86/newspeak.cog.spur/installer is code to make the .msi for a newspeak vm. And the corresponding thing exists for making the Mac OS .dmg. Any brace souls feel up to trying to get them together be built?
Just my 2c
Tim
On Thu, 1 Jun 2017, 06:05 Ben Coman, btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote:
>> On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote: >> >> On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote: >> 1) We need a stable branch, let’s say is Cog 2) We also need a >> development branch, let’s call it CogDev > IMHO, three branches are required as a minimum - stable, > integration and development because there are multiple primary > developers in core Pharo working on different OS platforms. but nobody will do the integration step so let’s keep it simple: integration is made responsibly for anyone who contributes, as it is done now.
I proposed only three *branches*, not people. Splitting development
into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference
between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
I just want to interject a check everyone's understanding of git
branches. Although I haven't used SVN, what I've read indicates SVN concepts can be hard to shake and git branching is conceptually very different from SVN.
The key thing is "a branch in Git is simply a lightweight movable pointer to a commit." The following article seems particularly useful to help frame our discussion... https://git-scm.com/book/en/v1/Git-Branching-What-a-Branch-Is
A branch is much the same as a tag, the are both references to a particular commit, except * branches are mutable references * tags are immutable references http://alblue.bandlem.com/2011/04/git-tip-of-week-tags.html
So if you want a moveable "good-vm" tag, maybe what you need is a branch reference.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs.
Agreed. But you want to deal with your own regressions not other
peoples. It seems harder to apply a "if you break it, you fix it" philosophy if its always broken.
The system must allow pushing an experiment through the build and test
pipeline to learn of a piece of development's impact.
IIUC, experimental branches (and PRs!!) can run through the CI pipeline
identical to the Cog branch (except maybe deployment step). There seems no benefit here for needing to commit directly to the Cog branch when a PR-commit would work the same.
An experiment may have to last for several months (for several reasons;
the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
This diagram may be a good reference for discussion, of how maintenance hotfixes can relate to development branches. http://1.bp.blogspot.com/-ct9MmWf5gJk/U2Pe9V8A5GI/AAAAAAAAAT0/0Y-XvAb9RB8/s1...
cheers -ben
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build?
For me a tested, version and named artefact is more useful than an all green build. An all red build is a red flag. A mostly green build is simply a failure to segregate production from in development artefacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
to show that the CI builds are cared for
allow newcomers to be confident that the tip they are working from is
green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
- act timely to integrate, to encourage further contributions. If
someone contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
Regards .. Subbu
On Thu, Jun 1, 2017 at 7:40 PM Ben Coman btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 10:38 PM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tim,
On May 31, 2017, at 11:53 PM, Tim Felgentreff timfelgentreff@gmail.com wrote:
Hi,
Just re the discussion of dev and stable branch, the original idea was that Cog is dev and master is stable. We never expected that people would use or recommend the Cog bintray builds for anything other than development.
But "master" ended up so far behind, recent changes would not get much
testing leading up to Pharo release... $ git log master 17 Aug 2016
That should be equivalent to 201608171728 [1], which is the first stable release we did on GitHub. We recently had to swap VMs in a Squeak bundle, which is why there is 201701281910 [2]. But I didn't want to flag this release as stable.
As Tim F. already mentioned, the initial idea was to use Cog as the dev branch, and the master for stable releases. Unfortunately, we don't have a working procedure for releasing new OpenSmalltalkVMs. I dared to create releases when we "had to" and after I asked Eliot for his recommendation. But it would be much nicer to have more frequent releases which our CI infrastructure allows us to do.
The CI already runs a selection of unit tests on some Squeak and Pharo VMs, and bootstraps Newspeak on some Newspeak VMs. The entry point is at [3], an example build at [4]. If this is not enough, we need to extend testing.
Currently, I would suggest to get the Cog branch green again by allowing all experimental VMs (e.g. sista) to fail on Travis. Then we could automate a merge from Cog to master when everything is green on Cog. Additionally, we could also automate GitHub releases, for example one release per month, considering that the more frequently updated VMs live on Bintray.
Best, Fabio
[1] https://github.com/OpenSmalltalk/opensmalltalk-vm/releases/tag/201608171728 [2] https://github.com/OpenSmalltalk/opensmalltalk-vm/releases/tag/201701281910 [3] https://github.com/OpenSmalltalk/opensmalltalk-vm/blob/Cog/.travis_test.sh [4] https://travis-ci.org/OpenSmalltalk/opensmalltalk-vm/jobs/237766261#L5256
You want to *encourage* people to use more recent VMs to get more feedback earlier.
I feel the only problem is that we need someone who merges to master when it is green. I think we have already protected the master branch in the way Ben suggested, i.e., you can only open a PR and merge it if the Travis build is all green.
I can do this. Ideally it would be either automatic or prompted. What I mean is that there should be a set of tests that are relevant n on images using the production subset of the VMs built from the Cog branch. Whenever the tests are all green then either I get sent an email prompting me to push to master, or a push to master occurs.
I think it would be useful to differentiate between different levels of stability depending on application and personal perspective. A. personal-stable -- stable "enough" for developer/student to use personally on their desktop -- might be optimistic if it passes all tests B. production-stable -- "bulletproof" for operating machinery and business systems - maybe when A has be in wide use for a while
btw, it occurs to be that "master" is a bit ambiguous. Perhaps for (B.) "master" could be renamed "production" https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/
and for (A.) maybe introduce "stable" or alternatively "validated" to mean all tests passed without the strong implication it is "stable".
Maybe I can get into the habit of checking the status of the build a few hours after a commit. But a generated email would compensate for my, um, it's on the tip of my tongue, um, my, my memory! And an automated push would allow me to resume walking in front of buses.
The bintray deployment should not be taken as a source of stable builds. It is meant to be used by what Eliot calls brave souls who want to help to test the latest and possibly unstable changes.
Good. This makes perfect sense to me. Are there places in the configuration to add brief overview texts explaining this to the bintray download pages? It would be great to have a short paragraph that says these are development versions and directs to the master builds.
P.S. for master builds Gilad has noticed that there is no .msi for the newspeak builds (and I suspect there may be no .dmg). In e.g. build.win32x86/newspeak.cog.spur/installer is code to make the .msi for a newspeak vm. And the corresponding thing exists for making the Mac OS .dmg. Any brace souls feel up to trying to get them together be built?
Just my 2c
Tim
On Thu, 1 Jun 2017, 06:05 Ben Coman, btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote: >>> On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote: >>> >>> On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote: >>> 1) We need a stable branch, let’s say is Cog 2) We also need a >>> development branch, let’s call it CogDev >> IMHO, three branches are required as a minimum - stable, >> integration and development because there are multiple primary >> developers in core Pharo working on different OS platforms. > but nobody will do the integration step so let’s keep it simple: > integration is made responsibly for anyone who contributes, as it is > done now.
I proposed only three *branches*, not people. Splitting development
into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference
between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
I just want to interject a check everyone's understanding of git
branches. Although I haven't used SVN, what I've read indicates SVN concepts can be hard to shake and git branching is conceptually very different from SVN.
The key thing is "a branch in Git is simply a lightweight movable pointer to a commit." The following article seems particularly useful to help frame our discussion... https://git-scm.com/book/en/v1/Git-Branching-What-a-Branch-Is
A branch is much the same as a tag, the are both references to a particular commit, except
- branches are mutable references
- tags are immutable references
http://alblue.bandlem.com/2011/04/git-tip-of-week-tags.html
So if you want a moveable "good-vm" tag, maybe what you need is a branch reference.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs.
Agreed. But you want to deal with your own regressions not other
peoples. It seems harder to apply a "if you break it, you fix it" philosophy if its always broken.
The system must allow pushing an experiment through the build and test
pipeline to learn of a piece of development's impact.
IIUC, experimental branches (and PRs!!) can run through the CI pipeline
identical to the Cog branch (except maybe deployment step). There seems no benefit here for needing to commit directly to the Cog branch when a PR-commit would work the same.
An experiment may have to last for several months (for several reasons;
the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
This diagram may be a good reference for discussion, of how maintenance hotfixes can relate to development branches.
http://1.bp.blogspot.com/-ct9MmWf5gJk/U2Pe9V8A5GI/AAAAAAAAAT0/0Y-XvAb9RB8/s1...
cheers -ben
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build?
For me a tested, version and named artefact is more useful than an all green build. An all red build is a red flag. A mostly green build is simply a failure to segregate production from in development artefacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
to show that the CI builds are cared for
allow newcomers to be confident that the tip they are working from is
green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
- act timely to integrate, to encourage further contributions. If
someone contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
Regards .. Subbu
Hi Fabio,
On Thu, Jun 1, 2017 at 11:58 AM, Fabio Niephaus lists@fniephaus.com wrote:
On Thu, Jun 1, 2017 at 7:40 PM Ben Coman btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 10:38 PM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tim,
On May 31, 2017, at 11:53 PM, Tim Felgentreff timfelgentreff@gmail.com wrote:
Hi,
Just re the discussion of dev and stable branch, the original idea was that Cog is dev and master is stable. We never expected that people would use or recommend the Cog bintray builds for anything other than development.
But "master" ended up so far behind, recent changes would not get much
testing leading up to Pharo release... $ git log master 17 Aug 2016
That should be equivalent to 201608171728 [1], which is the first stable release we did on GitHub. We recently had to swap VMs in a Squeak bundle, which is why there is 201701281910 [2]. But I didn't want to flag this release as stable.
As Tim F. already mentioned, the initial idea was to use Cog as the dev branch, and the master for stable releases. Unfortunately, we don't have a working procedure for releasing new OpenSmalltalkVMs. I dared to create releases when we "had to" and after I asked Eliot for his recommendation. But it would be much nicer to have more frequent releases which our CI infrastructure allows us to do.
The CI already runs a selection of unit tests on some Squeak and Pharo VMs, and bootstraps Newspeak on some Newspeak VMs. The entry point is at [3], an example build at [4]. If this is not enough, we need to extend testing.
Currently, I would suggest to get the Cog branch green again by allowing all experimental VMs (e.g. sista) to fail on Travis. Then we could automate a merge from Cog to master when everything is green on Cog.
+1. This should happen asap.
Additionally, we could also automate GitHub releases, for example one release per month, considering that the more frequently updated VMs live on Bintray.
+1
Best, Fabio
[1] https://github.com/OpenSmalltalk/opensmalltalk- vm/releases/tag/201608171728 [2] https://github.com/OpenSmalltalk/opensmalltalk- vm/releases/tag/201701281910 [3] https://github.com/OpenSmalltalk/opensmalltalk- vm/blob/Cog/.travis_test.sh [4] https://travis-ci.org/OpenSmalltalk/opensmalltalk- vm/jobs/237766261#L5256
You want to *encourage* people to use more recent VMs to get more feedback earlier.
I feel the only problem is that we need someone who merges to master when it is green. I think we have already protected the master branch in the way Ben suggested, i.e., you can only open a PR and merge it if the Travis build is all green.
I can do this. Ideally it would be either automatic or prompted. What I mean is that there should be a set of tests that are relevant n on images using the production subset of the VMs built from the Cog branch. Whenever the tests are all green then either I get sent an email prompting me to push to master, or a push to master occurs.
I think it would be useful to differentiate between different levels of stability depending on application and personal perspective. A. personal-stable -- stable "enough" for developer/student to use personally on their desktop -- might be optimistic if it passes all tests B. production-stable -- "bulletproof" for operating machinery and business systems - maybe when A has be in wide use for a while
btw, it occurs to be that "master" is a bit ambiguous. Perhaps for (B.) "master" could be renamed "production" https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/
and for (A.) maybe introduce "stable" or alternatively "validated" to mean all tests passed without the strong implication it is "stable".
Maybe I can get into the habit of checking the status of the build a few hours after a commit. But a generated email would compensate for my, um, it's on the tip of my tongue, um, my, my memory! And an automated push would allow me to resume walking in front of buses.
The bintray deployment should not be taken as a source of stable builds. It is meant to be used by what Eliot calls brave souls who want to help to test the latest and possibly unstable changes.
Good. This makes perfect sense to me. Are there places in the configuration to add brief overview texts explaining this to the bintray download pages? It would be great to have a short paragraph that says these are development versions and directs to the master builds.
P.S. for master builds Gilad has noticed that there is no .msi for the newspeak builds (and I suspect there may be no .dmg). In e.g. build.win32x86/newspeak.cog.spur/installer is code to make the .msi for a newspeak vm. And the corresponding thing exists for making the Mac OS .dmg. Any brace souls feel up to trying to get them together be built?
Just my 2c
Tim
On Thu, 1 Jun 2017, 06:05 Ben Coman, btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
> On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote: > > On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote: >>>> On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote: >>>> >>>> On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote: >>>> 1) We need a stable branch, let’s say is Cog 2) We also need a >>>> development branch, let’s call it CogDev >>> IMHO, three branches are required as a minimum - stable, >>> integration and development because there are multiple primary >>> developers in core Pharo working on different OS platforms. >> but nobody will do the integration step so let’s keep it simple: >> integration is made responsibly for anyone who contributes, as it is >> done now. > > I proposed only three *branches*, not people. Splitting development into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
> I will defer to your experience. I do understand the difference between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
I just want to interject a check everyone's understanding of git
branches. Although I haven't used SVN, what I've read indicates SVN concepts can be hard to shake and git branching is conceptually very different from SVN.
The key thing is "a branch in Git is simply a lightweight movable pointer to a commit." The following article seems particularly useful to help frame our discussion... https://git-scm.com/book/en/v1/Git-Branching-What-a-Branch-Is
A branch is much the same as a tag, the are both references to a particular commit, except
- branches are mutable references
- tags are immutable references
http://alblue.bandlem.com/2011/04/git-tip-of-week-tags.html
So if you want a moveable "good-vm" tag, maybe what you need is a branch reference.
And the previous paragraph applies equally to performance improvements, and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs.
Agreed. But you want to deal with your own regressions not other
peoples. It seems harder to apply a "if you break it, you fix it" philosophy if its always broken.
The system must allow pushing an experiment through the build and test
pipeline to learn of a piece of development's impact.
IIUC, experimental branches (and PRs!!) can run through the CI
pipeline identical to the Cog branch (except maybe deployment step). There seems no benefit here for needing to commit directly to the Cog branch when a PR-commit would work the same.
An experiment may have to last for several months (for several reasons;
the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
This diagram may be a good reference for discussion, of how maintenance hotfixes can relate to development branches. http://1.bp.blogspot.com/-ct9MmWf5gJk/U2Pe9V8A5GI/ AAAAAAAAAT0/0Y-XvAb9RB8/s1600/gitflow-orig-diagram.png
cheers -ben
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green
build? For me a tested, version and named artefact is more useful than an all green build. An all red build is a red flag. A mostly green build is simply a failure to segregate production from in development artefacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
to show that the CI builds are cared for
allow newcomers to be confident that the tip they are working from is
green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
- act timely to integrate, to encourage further contributions. If
someone contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
> Regards .. Subbu
On Friday 02 June 2017 12:28 AM, Fabio Niephaus wrote:
As Tim F. already mentioned, the initial idea was to use Cog as the dev branch, and the master for stable releases. Unfortunately, we don't have a working procedure for releasing new OpenSmalltalkVMs. I dared to create releases when we "had to" and after I asked Eliot for his recommendation.
I admit to feeling a bit confused about this 'master'.
But it would be much nicer to have more frequent releases which our CI infrastructure allows us to do.
+1. Eliot is right in proposing in an earlier post on taking a step back to look at the overall design now that we have Git and CI.
My understanding of a master branch is the opposite of what is described above :-(. In a typical project, it is the master (or trunk) branch which is under active development and receives a stream of feature and repair patches. At some point of stability, it undergoes a feature freeze and starts taking in only repairs. Freeze helps get more eyeballs on clearing bug backlog yielding a series of candidate releases culminating in 'public release', tagged and branched to a maintenance branch. The master is then opened up for feature patches and the cycle proceeds. Release branch is then actively maintained with security and compat patches for two cycles (so that git bisect can be used to trace regressions).
Regards .. Subbu
Hi Ben,
reading forward it seems I've miscommunicated what I mean by an experiment. By experiment I mean a Vm configuration not used for production, such as the Sista and Locoed VMs. I visit this below.
On Thu, Jun 1, 2017 at 10:40 AM, Ben Coman btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 10:38 PM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tim,
On May 31, 2017, at 11:53 PM, Tim Felgentreff timfelgentreff@gmail.com wrote:
Hi,
Just re the discussion of dev and stable branch, the original idea was that Cog is dev and master is stable. We never expected that people would use or recommend the Cog bintray builds for anything other than development.
But "master" ended up so far behind, recent changes would not get much
testing leading up to Pharo release... $ git log master 17 Aug 2016
You want to *encourage* people to use more recent VMs to get more feedback earlier.
Yes, but I disagree that the issue is the master/Cog distinction. The problem is that there is no mechanism to help remind us when to advance things to master. If that's present then we have no problems using the current structure.
I feel the only problem is that we need someone who merges to master when
it is green. I think we have already protected the master branch in the way Ben suggested, i.e., you can only open a PR and merge it if the Travis build is all green.
I can do this. Ideally it would be either automatic or prompted. What I mean is that there should be a set of tests that are relevant n on images using the production subset of the VMs built from the Cog branch. Whenever the tests are all green then either I get sent an email prompting me to push to master, or a push to master occurs.
I think it would be useful to differentiate between different levels of stability depending on application and personal perspective. A. personal-stable -- stable "enough" for developer/student to use personally on their desktop -- might be optimistic if it passes all tests
Sure. So the mechanism needed is running at least the test suite on a new VM right?
B. production-stable -- "bulletproof" for operating machinery and business systems - maybe when A has be in wide use for a while
Not sure we can do much more here than run the tests. What we can insist on is that a master commit should pass the tests on all supported platforms x all production VM configurations.
btw, it occurs to be that "master" is a bit ambiguous. Perhaps for (B.) "master" could be renamed "production" https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/
Well, what's in a name? "master" is fine for production. Tagging a particular master commit with a release id tag would be the necessary extra no?
and for (A.) maybe introduce "stable" or alternatively "validated" to mean all tests passed without the strong implication it is "stable".
Well, if the build and test steps are separated then there would hopefully be a page with green "tests passed" entries containing like to the VMs that passed the tests, no?
Maybe I can get into the habit of checking the status of the build a few
hours after a commit. But a generated email would compensate for my, um, it's on the tip of my tongue, um, my, my memory! And an automated push would allow me to resume walking in front of buses.
The bintray deployment should not be taken as a source of stable builds. It is meant to be used by what Eliot calls brave souls who want to help to test the latest and possibly unstable changes.
Good. This makes perfect sense to me. Are there places in the configuration to add brief overview texts explaining this to the bintray download pages? It would be great to have a short paragraph that says these are development versions and directs to the master builds.
P.S. for master builds Gilad has noticed that there is no .msi for the newspeak builds (and I suspect there may be no .dmg). In e.g. build.win32x86/newspeak.cog.spur/installer is code to make the .msi for a newspeak vm. And the corresponding thing exists for making the Mac OS .dmg. Any brace souls feel up to trying to get them together be built?
Just my 2c
Tim
On Thu, 1 Jun 2017, 06:05 Ben Coman, btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote:
On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote: >>> On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote: >>> >>> On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote: >>> 1) We need a stable branch, let’s say is Cog 2) We also need a >>> development branch, let’s call it CogDev >> IMHO, three branches are required as a minimum - stable, >> integration and development because there are multiple primary >> developers in core Pharo working on different OS platforms. > but nobody will do the integration step so let’s keep it simple: > integration is made responsibly for anyone who contributes, as it is > done now.
I proposed only three *branches*, not people. Splitting development
into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
I will defer to your experience. I do understand the difference
between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
I just want to interject a check everyone's understanding of git
branches. Although I haven't used SVN, what I've read indicates SVN concepts can be hard to shake and git branching is conceptually very different from SVN.
The key thing is "a branch in Git is simply a lightweight movable pointer to a commit." The following article seems particularly useful to help frame our discussion... https://git-scm.com/book/en/v1/Git-Branching-What-a-Branch-Is
The commit is related to a graph of previous commits, right? So a branch implies a distinct set of commits, right? When one merges from a branch, the commits on the branch don't get added to the target into which one merges do they Isn't that the difference between pull and pull -a, that the former just pulls commits on a single branch while pull -a p;pulls commits on all branches?
A branch is much the same as a tag, the are both references to a particular commit, except
- branches are mutable references
- tags are immutable references
http://alblue.bandlem.com/2011/04/git-tip-of-week-tags.html
So if you want a moveable "good-vm" tag, maybe what you need is a branch reference.
But isn't that what master is supposed to be?
And the previous paragraph applies equally to performance improvements, and
functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs.
Agreed. But you want to deal with your own regressions not other
peoples. It seems harder to apply a "if you break it, you fix it" philosophy if its always broken.
To reiterate, distinguishing between the production set and the experimental set is what's necessary here.
The system must allow pushing an experiment through the build and test
pipeline to learn of a piece of development's impact.
IIUC, experimental branches (and PRs!!) can run through the CI pipeline
identical to the Cog branch (except maybe deployment step). There seems no benefit here for needing to commit directly to the Cog branch when a PR-commit would work the same.
No, not experimental branches. Experimental configurations. Sista and LowCode are currently experiments. We don't care if these are broken; they're not part of the production VM set yet. So Clément, Ronie and myself should be able to modify, including break, these configurations without hindrance, and without generating noise for the community.
An experiment may have to last for several months (for several reasons;
the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
This diagram may be a good reference for discussion, of how maintenance hotfixes can relate to development branches. http://1.bp.blogspot.com/-ct9MmWf5gJk/U2Pe9V8A5GI/ AAAAAAAAAT0/0Y-XvAb9RB8/s1600/gitflow-orig-diagram.png
Makes perfect sense. The thing this doesn't mention is the ability to have experiential configurations live alongside the code being worked on for a stable release.
cheers -ben
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green build?
For me a tested, version and named artefact is more useful than an all green build. An all red build is a red flag. A mostly green build is simply a failure to segregate production from in development artefacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
to show that the CI builds are cared for
allow newcomers to be confident that the tip they are working from is
green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
- act timely to integrate, to encourage further contributions. If
someone contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
Regards .. Subbu
On Fri, Jun 2, 2017 at 7:36 AM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Ben,
reading forward it seems I've miscommunicated what I mean by anexperiment. By experiment I mean a Vm configuration not used for production, such as the Sista and Locoed VMs. I visit this below.
ah, gotcha. I was thinking more along the lines of short lived experiments where things might break to before fully understanding the impact.
On Thu, Jun 1, 2017 at 10:40 AM, Ben Coman btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 10:38 PM, Eliot Miranda eliot.miranda@gmail.com wrote:
Hi Tim,
On May 31, 2017, at 11:53 PM, Tim Felgentreff timfelgentreff@gmail.com wrote:
Hi,
Just re the discussion of dev and stable branch, the original idea was that Cog is dev and master is stable. We never expected that people would use or recommend the Cog bintray builds for anything other than development.
But "master" ended up so far behind, recent changes would not get much
testing leading up to Pharo release... $ git log master 17 Aug 2016
You want to *encourage* people to use more recent VMs to get more feedback earlier.
Yes, but I disagree that the issue is the master/Cog distinction. The problem is that there is no mechanism to help remind us when to advance things to master. If that's present then we have no problems using the current structure.
Okay. If master is kept reasonably up to date, then this concern goes away.
I feel the only problem is that we need someone who merges to master when
it is green. I think we have already protected the master branch in the way Ben suggested, i.e., you can only open a PR and merge it if the Travis build is all green.
I can do this. Ideally it would be either automatic or prompted. What I mean is that there should be a set of tests that are relevant n on images using the production subset of the VMs built from the Cog branch. Whenever the tests are all green then either I get sent an email prompting me to push to master, or a push to master occurs.
I think it would be useful to differentiate between different levels of stability depending on application and personal perspective. A. personal-stable -- stable "enough" for developer/student to use personally on their desktop -- might be optimistic if it passes all tests
Sure. So the mechanism needed is running at least the test suite on a new VM right?
Yes. This already happens on the Cog branch doesn't it? It just hasn't seemed a priority to keep it green.
B. production-stable -- "bulletproof" for operating machinery and business systems - maybe when A has be in wide use for a while
Not sure we can do much more here than run the tests. What we can insist on is that a master commit should pass the tests on all supported platforms x all production VM configurations.
Just an aside: A dream scenario would be something like PharoLauncher also managing VMs as well as Images, gathering statistics on {OS. VM. Image} tuples started and crashed, reporting aggregate statistics to users to facilitate users (ranged across the technology adoption bell curve) to organically identify particular builds as real-world-tested-stable. But I'm not sure how workable that would be.
btw, it occurs to be that "master" is a bit ambiguous. Perhaps for (B.) "master" could be renamed "production" https://stevebennett.me/2014/02/26/git-what-they-didnt-tell-you/
Well, what's in a name? "master" is fine for production. Tagging a particular master commit with a release id tag would be the necessary extra no?
and for (A.) maybe introduce "stable" or alternatively "validated" to mean all tests passed without the strong implication it is "stable".
Well, if the build and test steps are separated then there would hopefully be a page with green "tests passed" entries containing like to the VMs that passed the tests, no?
okay. just floating ideas.
Maybe I can get into the habit of checking the status of the build a few
hours after a commit. But a generated email would compensate for my, um, it's on the tip of my tongue, um, my, my memory! And an automated push would allow me to resume walking in front of buses.
The bintray deployment should not be taken as a source of stable builds. It is meant to be used by what Eliot calls brave souls who want to help to test the latest and possibly unstable changes.
Good. This makes perfect sense to me. Are there places in the configuration to add brief overview texts explaining this to the bintray download pages? It would be great to have a short paragraph that says these are development versions and directs to the master builds.
P.S. for master builds Gilad has noticed that there is no .msi for the newspeak builds (and I suspect there may be no .dmg). In e.g. build.win32x86/newspeak.cog.spur/installer is code to make the .msi for a newspeak vm. And the corresponding thing exists for making the Mac OS .dmg. Any brace souls feel up to trying to get them together be built?
Just my 2c
Tim
On Thu, 1 Jun 2017, 06:05 Ben Coman, btc@openinworld.com wrote:
On Thu, Jun 1, 2017 at 2:27 AM, Nicolas Cellier < nicolas.cellier.aka.nice@gmail.com> wrote:
2017-05-31 17:31 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
Hi All,
> On May 31, 2017, at 1:54 AM, K K Subbu kksubbu.ml@gmail.com wrote: > > On Wednesday 31 May 2017 12:35 PM, Esteban Lorenzano wrote: >>>> On 31 May 2017, at 09:01, K K Subbu kksubbu.ml@gmail.com wrote: >>>> >>>> On Wednesday 31 May 2017 12:18 PM, Esteban Lorenzano wrote: >>>> 1) We need a stable branch, let’s say is Cog 2) We also need a >>>> development branch, let’s call it CogDev >>> IMHO, three branches are required as a minimum - stable, >>> integration and development because there are multiple primary >>> developers in core Pharo working on different OS platforms. >> but nobody will do the integration step so let’s keep it simple: >> integration is made responsibly for anyone who contributes, as it is >> done now. > > I proposed only three *branches*, not people. Splitting development into two branches and builds will help in isolating faster (separation of concerns). If all issues get cleared in dev branch itself, then integration branch will still be useful in catching regressions.
I don't believe this. Since the chain is VMMaker.oscog => opensmalltalk/vm => CI, clumping commits together when pushing from, say, CogDev to Cog doesn't help in identifying where things broke in VMMaker. This is why Esteban has implemented a complete autobuild path run on each VMMaker.oscog commit.
But, while this is a good thing, it isn't adequate because a) important changes are made to opensmalltalk/vm code independent of VMMaker.oscog b) sometimes one /has/ to break things to have them properly tested (e.g. the new compactor). i.e. there has to be a way of getting some experimental half-baked thing through the build pipeline so brace souls can test them
> I will defer to your experience. I do understand the difference between logical and practical in these matters.
Let's take a step back and instead of discussing implementation, discuss design.
For me, a VM is good not when someone says it is, not when it builds on all platforms, but when extensive testing finds no faults in it. For me this implies tagging versions in opensmalltalk/vm (which by design index the corresponding VMMaker.oscog because generated source is stamped with VMMaker.oscog version info) rather than using branches.
Further, novel bugs are found in VMs that are considered good, and these bugs should, if possible, be added to a test suite. This points to a major deficiency in our ability to tests VMs. We have no way to test the UI automatically. We have to use humans to produce mouse clicks and keystrokes. For me this implies tagging releases, and the ability to state that a given VM supersedes a previous known good VM.
I just want to interject a check everyone's understanding of git
branches. Although I haven't used SVN, what I've read indicates SVN concepts can be hard to shake and git branching is conceptually very different from SVN.
The key thing is "a branch in Git is simply a lightweight movable pointer to a commit." The following article seems particularly useful to help frame our discussion... https://git-scm.com/book/en/v1/Git-Branching-What-a-Branch-Is
The commit is related to a graph of previous commits, right? So a branch implies a distinct set of commits, right?
As a second order effect yes, a branch pointing at a single commit implies the set of all its ancestors. I just found that page particularly enlightening... "Because a branch in Git is in actuality a simple file that contains the 40 character SHA-1 checksum of the commit it points to, branches are cheap to create and destroy. Creating a new branch is as quick and simple as writing 41 bytes to a file (40 characters and a newline)."
When one merges from a branch, the commits on the branch don't get added to
the target [branch] into which one merges do they
I've had trouble trouble parsing that. On one hand, it might be considered that commits on the source branch *are* added to the target branch. One the other hand, it sounds like you concur that branches aren't a set of commits (since git under the hood has no "sets") - just the code of two specific commits being merged to create a new commit, to which the target branch reference is moved to.
Isn't that the difference between pull and pull -a, that the former just pulls commits on a single branch while pull -a p;pulls commits on all branches?
Sorry I don't know. I never use `git pull`, rather always `git fetch` + `git merge` after some advice I read to get more flexibility and a chance to review changes first. I search extensively but really could only find regurgitation of this copied from the man-page... "-a --append Append ref names and object names of fetched refs to the existing contents of .git/FETCH_HEAD. Without this option old data in .git/FETCH_HEAD will be overwritten." which I don't understand.
A branch is much the same as a tag, the are both references to a particular
commit, except
- branches are mutable references
- tags are immutable references
http://alblue.bandlem.com/2011/04/git-tip-of-week-tags.html
So if you want a moveable "good-vm" tag, maybe what you need is a branch reference.
But isn't that what master is supposed to be?
It seems a better process for master is underway, so okay.
And the previous paragraph applies equally to performance improvements,
and functionality enhancements, not just bugs.
Test suites and build chains catch regressions. Regressions in functionality and in performance are _useful information_ for developers trying to improve things, not necessarily an evil to be avoided at all costs.
Agreed. But you want to deal with your own regressions not other
peoples. It seems harder to apply a "if you break it, you fix it" philosophy if its always broken.
To reiterate, distinguishing between the production set and the experimental set is what's necessary here.
After being a bit slow, now got it.
The system must allow pushing an experiment through the build and test
pipeline to learn of a piece of development's impact.
IIUC, experimental branches (and PRs!!) can run through the CI
pipeline identical to the Cog branch (except maybe deployment step). There seems no benefit here for needing to commit directly to the Cog branch when a PR-commit would work the same.
No, not experimental branches. Experimental configurations. Sista and LowCode are currently experiments. We don't care if these are broken; they're not part of the production VM set yet. So Clément, Ronie and myself should be able to modify, including break, these configurations without hindrance, and without generating noise for the community.
okay. got it.
An experiment may have to last for several months (for several reasons;
the new compactor is a good example: some bugs show up in unusual circumstances; some bugs are hard to fix).
Another requirement is to provide a stable point for someone to begin new work. They need to know that their starting point is not an experiment in progress. They need to understand that the cost of working on what is effectively a branch from the trunk is an integration step(s) into trunk layer on, and this can't be just at the opensmalltalk/vm level using fit to assist the merge, but also at the VMMaker.oscog level using Monticello to merge. Both are good at supporting merges because both support identifying the set of changes. Both are poor at supporting merges because they don't understand refactoring and currently only humans can massage a set of changes forwards applying refactorings to a set of changes. This is what real merges are, and the reason why git only eases the trivial cases and why real programmers use a lot more tools to merge than just a vcs.
Can others add additional requirements, or critique the above requirements? (Try not to mention git or ci implementations when you do). ======
With the above said what seems lacking to me is the testing framework for completed VMs. A build not can identify commits that fail a build and also produce a VM for subsequent packaging and/or testing. Separating the steps is very useful here. A long pipeline with a single red or green light at the end is much less useful than a series of short pipelines, each with a separate red or green light. Reading through a bot log to identify precisely where things broke is both tedious and, more importantly, not useful in an automated system because that identification is manual. Separate short pipelines can be used to inform an automatic system (right Bob? Bob Westergaard built the testing system at Cadence and that is constructed from lots of small steps and it isolates faults nicely; something that an end-to-end system like Esteban's doesn't do as well).
Now, if we have a long sequence of nicely separated generate, build, package, test steps how many separate pipelines do we need to be able to collaborate? Is it enough to be able to tag an upstream artifact as having passed some or all of its downstream tests or do we need to be able to duplicate the pipeline so people can run independent experiments?
For me, I see two modes of development; new development and maintenance. New development is fine in a fork in some subset of the full build chain. e.g. when working on Spur I forked within VMMaker.oscog (and, unfortunately, in part because we didn't have opensmalltalk/vm or many of the above requirements discussed, let alone met, I would break V3 for much of the time). e.g. the new compactor was forked in VMMaker.oscog without breaking Esteban's chain by my using a special generation step controlled by a switch I set in my branch. I tested in my own sandbox until the new compactor needed testing by a wider audience.
Maintenance is some relatively quick fix one (thinks one) can safely apply to either VMMaker.oscog or opensmalltalk/vm trunk to address some issue.
Forking is fine for new development if a) people understand and are prepared to pay the cost of merging, or, better, b) they can use switches to include their work as optional in trunk There are lots of switches: A switch between versions in VMMaker.oscog, e.g. Spur memory manager vs V3, or the new Spur compactor vs the old, or the Sista JIT vs the standard, etc A switch between a vm configuration, e.g. pharo.cog.spur vs squeak.cog.spur in a build directory, which can do any of
- select a generated source tree (e.g. spursrc vs spur64src)
- use #ifdef's to select code in the C source
- use plugins.int & plugins.ext to select a set of plugins
A switch between dialects (Pharo vs Squeak vs Newspeak) A switch between platforms (Mac OS X vs win32, Linux x64 vs Linux ARM)
I get the above distinctions and know how to navigate amongst them upstream, but don't understand very well the downstream (how to clone the build/test CI pipeline so I can cheaply fork, work on the branch and then merge). So I'm happier using switches to try and hide new work in trunk to avoid derailing people. And so I prefer the notion of a single pipeline that tags specific versions as good.
Is one of the requirements that people want to clearly separate maintenance from new development?
This diagram may be a good reference for discussion, of how maintenance hotfixes can relate to development branches. http://1.bp.blogspot.com/-ct9MmWf5gJk/U2Pe9V8A5GI/AAAAAAAAAT 0/0Y-XvAb9RB8/s1600/gitflow-orig-diagram.png
Makes perfect sense. The thing this doesn't mention is the ability to have experiential configurations live alongside the code being worked on for a stable release.
I guess experimental configurations are orthogonal - more of a build issue. Ideally adding features to an experimental configuration would still be done using a PR from a feature branch so the CI tests ensure no problems leaked out of their #ifdefs, but without that, experimental configurations is still a good step.
cheers -ben
Is one of the requirements that people want to clearly identify which commit caused a specific bug? (Big discussion here about major, e.g. V3 => Spur transitions vs small grain changes; you can identify the latter, but not necessarily the former).
I suppose what I'm asking is what's the benefit of an all green
build? For me a tested, version and named artefact is more useful than an all green build. An all red build is a red flag. A mostly green build is simply a failure to segregate production from in development artefacts.
Hi Eliot, the main advantage of github is the social thing:
- lower barrier of contributing via a better integration of tools
(not only vcs, but issue tracker, wiki, continuous integration, code review/comments and pull request - even if we under use most of these tools),
- and ease integration of many small contributions back.
For this to work well, such work MUST happen in separate branches. in this context, there is an obvious benefit of green build: quickly estimate if we can merge a pull request or not. when red, we have no information about possible regressions, and have to go through the tedious part: go down into the console log of both builds, try to understand and compare... There is already enough work involved in reviewing source code.
I see that my opening argument was simplistic. However Nicolas' point above is probably more significant. If we want to encourage new contributors, we need:
to show that the CI builds are cared for
allow newcomers to be confident that the tip they are working from is
green before they start. When they submit their PR and the CI tests fail, they should be able to zero in the failures *they* caused and *as*a*newbie* not have to sort through the confounding factors from other's failures.
- act timely to integrate, to encourage further contributions. If
someone contributes a good fix, a green CI test may make you inclined to quickly review and integrate. But when the CI shows failure, how will you feel about looking into it? Further, when the mainline returns to green, the existing PRs don't automatically retest, and no-one seems to be manually managing them, so such PRs seem to end up in limbo which is *really* discouraging for potential contributors.
cheers -ben
I tend to agree on your view for mid/long term changes: Say a developper A works on new garbage collector, developper B on 64bits compatibility, developer C on lowcode extension and developer D on sista (though maybe there is a single developper touching 3 of these) Since each of these devs are going to take months, and touch many core methods scattered in interpreter/jit/object memory or CCodeGenerator, then it's going to be very difficult to merge (way too many conflicts).
If on different branches, there is the option to rebase or merge with other branches. But it doesn't scale with N branches touching same core methods: N developpers would have to rebase on N-1 concurrent branches, resolve the exact same conflicts etc... Obviously, concurrent work would have to be integrated back ASAP in a master branch.
So, a good branch is a short branch, if possible covering a minimal feature set. And long devs you describe must not be handled by branches, but by switches. This gives you a chance to inspect the impact of your own refactoring on your coworkers.
In this model, yes, you have a license to break your own artifact (say generationalScavenger, win64, lowcode, sista). But you must be informed if ever you broke the production VM, and/or concurrent artifacts. You have to maintain a minimal set of features working, otherwise you prevent others to work. In the scavenger case, you used a branch for a short period, and that worked quite well.
In this context, I agree, a single green light is not enough. We need a sort of status board tracing the regressions individually.
> Regards .. Subbu
-- _,,,^..^,,,_ best, Eliot
Ben and Eliot, just in case you missed Jacobs answer to the git pull -a question (which you both seem to be confused about)
On Fri, 2 Jun 2017 at 10:00 Jakob Reschke jakob.reschke@student.hpi.de wrote:
2017-06-02 1:36 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
...
The commit is related to a graph of previous commits, right? So a branch implies a distinct set of commits, right? When one merges from a branch, the commits on the branch don't get added to the target into which one merges do they Isn't that the difference between pull and pull -a, that the former just pulls commits on a single branch while pull -a p;pulls commits on all branches?
Git commits refer to their parent commits (merge commits have more than one parent), but do not store on which branch(es) they are or were on. Since a branch is just a reference (to a commit), you may talk about the commits that are reachable from a branch (it is what you get from "git log branchname"). But this set almost always overlaps with that of other branches because of all the common ancestor commits.
Merging a branch adds an additional parent to the to-be-created merge commit. Thus, the commits from the merged branch become reachable from the branch into which you are merging. So, in a way, they do get added to the merge target.
pull -a does not "pull on all branches" and does not usually affect the result of the merge at all. "git pull <remote> <branch>" essentially means "git fetch <remote> <branch>", which writes the fetched commits to a temporary reference called FETCH_HEAD, followed by "git merge FETCH_HEAD". The -a stands for --append, is an option for the fetch, and means that instead of overwriting what is in .git/FETCH_HEAD, append the newly fetched commits there. But "git merge FETCH_HEAD" will only use the top commit from that file anyway, so this is kind of pointless for pull. In fact, it might lead to merging the wrong branch or not merging anything at all because the latest fetched commit with -a goes to the end of FETCH_HEAD, not the top.
But even if it meant to "pull commits on all branches", why would that be useful? When you work and pull on branch/feature X, why would you want to invoke a merge on an unrelated branch/feature Y?
If you wanted to merge more than one upstream branch into your current branch, you would have to name them all when pulling:
git pull origin branch1 branch2 ...
...which attempts a merge with (1 + number of unmerged upstream branches named on the command line) parent commits.
Yes, that helped. Thx Jacob.
On Sun, Jun 4, 2017 at 4:56 PM, Tim Felgentreff timfelgentreff@gmail.com wrote:
Ben and Eliot, just in case you missed Jacobs answer to the git pull -a question (which you both seem to be confused about)
On Fri, 2 Jun 2017 at 10:00 Jakob Reschke jakob.reschke@student.hpi.de wrote:
2017-06-02 1:36 GMT+02:00 Eliot Miranda eliot.miranda@gmail.com:
...
The commit is related to a graph of previous commits, right? So a
branch
implies a distinct set of commits, right? When one merges from a
branch,
the commits on the branch don't get added to the target into which one merges do they Isn't that the difference between pull and pull -a, that the former just pulls commits on a single branch while pull -a p;pulls commits on all branches?
Git commits refer to their parent commits (merge commits have more than one parent), but do not store on which branch(es) they are or were on. Since a branch is just a reference (to a commit), you may talk about the commits that are reachable from a branch (it is what you get from "git log branchname"). But this set almost always overlaps with that of other branches because of all the common ancestor commits.
Merging a branch adds an additional parent to the to-be-created merge commit. Thus, the commits from the merged branch become reachable from the branch into which you are merging. So, in a way, they do get added to the merge target.
pull -a does not "pull on all branches" and does not usually affect the result of the merge at all. "git pull <remote> <branch>" essentially means "git fetch <remote> <branch>", which writes the fetched commits to a temporary reference called FETCH_HEAD, followed by "git merge FETCH_HEAD". The -a stands for --append, is an option for the fetch, and means that instead of overwriting what is in .git/FETCH_HEAD, append the newly fetched commits there. But "git merge FETCH_HEAD" will only use the top commit from that file anyway, so this is kind of pointless for pull. In fact, it might lead to merging the wrong branch or not merging anything at all because the latest fetched commit with -a goes to the end of FETCH_HEAD, not the top.
But even if it meant to "pull commits on all branches", why would that be useful? When you work and pull on branch/feature X, why would you want to invoke a merge on an unrelated branch/feature Y?
If you wanted to merge more than one upstream branch into your current branch, you would have to name them all when pulling:
git pull origin branch1 branch2 ...
...which attempts a merge with (1 + number of unmerged upstream branches named on the command line) parent commits.

The commit is related to a graph of previous commits, right? So a branch implies a distinct set of commits, right? When one merges from a branch, the commits on the branch don't get added to the target into which one merges do they Isn't that the difference between pull and pull -a, that the former just pulls commits on a single branch while pull -a p;pulls commits on all branches?
Git repository is just a big key-value store. Keyed under SHA1 of their contents, the following kinds of values are stored - files, trees objects and commit objects. Files are themselves. Tree objects contain list of files and other tree objects. Commit objects contain a list of other commit objects and tree objects.
I think it is nicely explained in the official git book: https://git-scm.com/book/en/v2/Git-Internals-Git-Objects%5B10.2 Git Internals - Git Objects].
Commits are lists of SHA1s of other objects in the store. Each commit stores the SHA1 for its ancestor commit and/or any merged in commit.
Each branch is a pointer to a SHA1. When you commit to a branch, a new commit object is created. The object for the commit is stored under its SHA1 and the branch pointer is set to this new SHA1.
Any commit you know the SHA1 of can be compared/merged to/from any other commit you know the SHA1 of.
The branches serve just like a pointer to a SHA1 that gets moved each time you make a commit to the branch. Since each commit contains a pointer the SHA1 of its ancestor and any commit merged from, you can walk the history with 'git log SHA1'.
When you merge a commit, both the ancestors' SHA1 and the merged's SHA1 are added to the list of SHA1s that form the commit.
Best Regards,
Milan Vavra
-- View this message in context: http://forum.world.st/the-purpose-of-CI-tp4948482p4949264.html Sent from the Squeak VM mailing list archive at Nabble.com.
vm-dev@lists.squeakfoundation.org
-
 Ben Coman
Ben Coman -
 Eliot Miranda
Eliot Miranda -
 Esteban Lorenzano
Esteban Lorenzano -
 Fabio Niephaus
Fabio Niephaus -
 K K Subbu
K K Subbu -
 Milan Vavra
Milan Vavra -
 Nicolas Cellier
Nicolas Cellier -
 Tim Felgentreff
Tim Felgentreff -
 Tobias Pape
Tobias Pape